Challenge Significance
The rapid evolution of AIGC technologies has transformed document tampering into a sophisticated threat that blends visual forgery with high-level semantic manipulation. The GenText-Forensics Challenge is established to address these emerging risks through three strategic objectives:
- Pioneering Multilingual Text-Centric Forensics: While traditional forensics focuses on low-level visual anomalies, this challenge addresses the under-explored domain of text-rich image security. By shifting the paradigm from simple binary detection to a unified forgery analysis task, we aim to tackle covert threats like "visually similar character substitution" that can trigger cascading poisoning risks across OCR–LLM pipelines.
- Establishing a Robust Multimodal Benchmark: By leveraging the RealText-V2 dataset—the world's first large-scale, multilingual (6 languages) and multi-domain benchmark—the challenge provides a standardized platform to evaluate defensive models against 100+ sophisticated attack methods. This accelerates the transition from laboratory research to reliable, real-world information security applications.
- Advancing Explainable AI (XAI) for Information Security: Aligning with the "AI for Good" ethos and the ACM MM mission, this challenge emphasizes the creation of complete evidence chains. By requiring participants to generate structured forensic reports that integrate detection, localization, and natural language reasoning, we foster the development of transparent and accountable AI solutions essential for highly regulated sectors like finance and healthcare.
Competition Rules and Incentives
1. Model Submission Requirements
- Integrated Functionality: We do not impose limits on the internal architecture or the number of models used within a solution. However, the proposed system must demonstrate a unified capability to execute all core tasks—detection, spatial grounding, and natural language explanation—simultaneously. The output must be a cohesive forensic report that reflects a joint modeling approach to evidence chain synthesis.
- Open-Source Frameworks: All submissions must be built upon open-source pre-trained architectures. Teams developing proprietary models during the challenge are required to release their model specifications and training protocols under recognized open-source licenses (e.g., MIT, Apache 2.0) prior to the competition's conclusion.
- Reproducibility & Transparency: Winning teams are mandated to open-source their complete implementations. This includes:
- End-to-end training pipelines and precise hyperparameter configurations.
- Standardized evaluation code and detailed reproducibility documentation.
- Final model weights provided in industry-standard formats.
2. Data Usage and Augmentation
- Strict Data Limitation: To ensure a fair and controlled benchmarking environment, participants are strictly prohibited from using any external datasets for training. All experimental and training workflows must rely exclusively on the official RealText-V2 dataset.
- In-Dataset Augmentation: Participants are encouraged to innovate through data augmentation or the generation of synthetic samples, provided they are derived solely from the RealText-V2 dataset.
- Methodological Disclosure: To maintain the integrity of the challenge, all tools, scripts, and generative prompts used for such in-dataset augmentation must be submitted alongside the final solution for verification and reproducibility checks.
3. Compliance and Authority
- Strict Adherence: Any violation of the aforementioned rules, including plagiarism or the use of undisclosed proprietary data, will result in immediate disqualification.
- Final Authority: The GenText-Forensics organizing committee reserves the final authority over all competition-related decisions, including rule interpretations and final ranking validations.
Challenge Task: Forgery Analysis Report Generation
This challenge focuses on the comprehensive analysis of text-centric forgeries. Participants are required to develop systems that automatically generate a structured forensic analysis report in Markdown format for a given text-rich image.
Forgery Analysis Report Generation
- Requiring the generation of comprehensive reports that integrate detection, spatial grounding, and natural language explanation.
Evaluation Metrics
The evaluation measures performance across four distinct dimensions:
- Detection (SDet): We use the standard F1-Score to measure the trade-off between Precision and Recall.
- Grounding (SLoc): To evaluate localization precision, we calculate the Pixel-level F1-Score (mF1) and mean Intersection over Union (mIoU) based on the intersection between predicted masks and Ground Truth masks, strictly adhering to the protocol in TruFor.
- Explanation (SExp): This metric evaluates the linguistic quality and semantic fidelity of the generated explanation. We utilize BERTScore to calculate the semantic similarity between the participant's generated text and the expert-annotated ground truth explanation.
- Report Quality Rubrics (SRep): We employ an advanced LLM Judge (e.g., Qwen3-MAX or GPT-4o) to conduct a rubric-based evaluation. We define fine-grained scoring rubrics (normalized to 0-100) covering three critical dimensions: Factuality (accuracy of verdict and evidence), Reasoning (logical deduction from visual clues), and Completeness (coverage of manipulated regions and format compliance).
The final ranking is determined by a weighted sum of the four components:
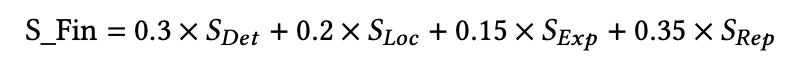
Submission Formats
Forgery Analysis Report Generation
To ensure seamless automated evaluation, all participants must follow a unified submission protocol. The final submission must be a single compressed file named prediction.jsonl.gz.
1. File Format & Packaging
The submission must be a JSON Lines (.jsonl) file where each line is a valid JSON object representing one test image.
image_name: (String) The exact filename of the test image.report: (String) The complete forensic analysis report in Markdown format, embedded as an escaped string.
Submission Workflow:
- Generate the Markdown report for each image.
- Package
image_nameandreportinto a.jsonlfile. - Compress the file using Gzip:
gzip prediction.jsonl→prediction.jsonl.gz.
2. Report Structure Requirements
The report string must strictly adhere to the following schema. The LLM Judge relies on specific tags (e.g., [...]) to extract data for scoring.
I. Overall Assessment
This section provides the high-level verdict.
- [Conclusion]: Clearly declare the status as FORGED or AUTHENTIC.
- [RISK_SCORE]: A numerical confidence score (0–100) representing the likelihood of manipulation.
II. Detailed Anomaly Analysis
For each detected forgery, participants must create an anomaly entry (e.g., ### ANOMALY_001). Each entry must contain:
- [GROUNDING]: Normalized bounding box coordinates in the format
[xmin, ymin, xmax, ymax]. - [REASON]: A natural language explanation detailing visual artifacts (e.g., clumsy patching, noise inconsistency) and semantic contradictions (e.g., logical errors, identity fraud).
III. Summary
A final synthesis of the findings, summarizing how the identified anomalies collectively support the overall assessment.
3. Parsing & Evaluation Notice (Strict Compliance)
- Schema Strictness: Reports failing to use the exact tags (e.g., using
[Result]instead of[Conclusion]) will result in parsing failures and a score of zero for that sample. - Coordinate Accuracy: Grounding coordinates must be normalized relative to the image dimensions.
- String Escaping: Since the Markdown report contains newlines (
\n) and quotes ("), ensure the string is correctly escaped within the JSON object.
4. Comprehensive Submission Example
Single Line in prediction.jsonl (Visual Representation):
{
"image_name": "sample_document_001.jpg",
"report": "# FORGERY ANALYSIS REPORT\n\n**Overall Assessment:**\n **[Conclusion]:** FORGED\n **[RISK_SCORE]:** 73\n\n---\n\n## DETAILED ANOMALY ANALYSIS\n\n### ANOMALY_001: Visual Clumsy Alteration\n[GROUNDING]: [1081, 933, 1288, 998]\n[REASON]: A crude, solid black rectangular block has been applied to obscure the phone number. The sharp edges and uniform color create a clear discontinuity with the surrounding texture.\n\n### ANOMALY_002: Logical Fraud\n[GROUNDING]: [1372, 585, 1630, 655]\n[REASON]: The document states the meeting is at '5:00 a.m.', which contradicts standard business practice. The font of 'a.m.' shows slight misalignment, suggesting digital alteration.\n\n---\n\n## SUMMARY\nThe document identified 2 distinct anomalies. The forgery pattern involves a mix of crude redactions and logical inconsistencies.\n\n**END OF REPORT**"
}5. Summary of Mandatory Tags
| Category | Mandatory Markdown Tag | Expected Value |
|---|---|---|
| Verdict | **[Conclusion]:** |
FORGED or AUTHENTIC |
| Confidence | **[RISK_SCORE]:** |
Integer 0 to 100 |
| Location | [GROUNDING]: |
[xmin, ymin, xmax, ymax] |
| Explanation | [REASON]: |
String (Natural Language) |